Event Storming антипаттерны
Когда доска выглядит как техническая схема
Симптомы
Сессия закончилась. Разработчики довольны — у них теперь есть схема для реализации.
Но ты смотришь на доску и видишь события:
Вроде доска заполнена, события разложены по таймлайну, вроде все верно, но есть ощущение, что что-то пошло не так.
И проблема действительно есть.
Но ты смотришь на доску и видишь события:
- EmployeeCreated, UserAccountCreated, PermissionsUpdated, EmailSent.
- Акторы — HR-система, UserService.
- Команды — POST /employees, PATCH /users/{id}/permissions.
Вроде доска заполнена, события разложены по таймлайну, вроде все верно, но есть ощущение, что что-то пошло не так.
И проблема действительно есть.

Такое случается, когда Event Storming воспринимается как инструмент для документирования системы, а не для исследования бизнес-процесса. Команда мыслит от системы — «что делает наш код?» — вместо того чтобы мыслить от процесса — «что происходит в бизнесе?». В итоге доска отражает архитектуру системы, а не поведение предметной области.
Результат: система строится под текущее понимание кода, а не под реальные бизнес-сценарии.
Через полгода выясняется, что EmployeeCreated на самом деле покрывает три разных ситуации — онбординг, перевод и восстановление аккаунта — и у каждой своя логика. Переделывать приходится дорого.
Ниже — шесть антипаттернов, которые превращают сессию в технический митинг, чек-листы для диагностики и практический роадмап исправления.
Результат: система строится под текущее понимание кода, а не под реальные бизнес-сценарии.
Через полгода выясняется, что EmployeeCreated на самом деле покрывает три разных ситуации — онбординг, перевод и восстановление аккаунта — и у каждой своя логика. Переделывать приходится дорого.
Ниже — шесть антипаттернов, которые превращают сессию в технический митинг, чек-листы для диагностики и практический роадмап исправления.
Быстрый чек-лист
Если совпало три и более пункта — у вас не настоящий Event Storming.
- В названиях событий есть слова: Created, Updated, Deleted, Saved, Sent
- На доске упоминаются технологии: HTTP, SQL, REST, Redis, Kafka, PostgreSQL
- Акторы — системы или сервисы, а не бизнес-роли
- Команды выглядят как endpoint'ы: POST /users, PATCH /orders/{id}
- После трёх часов работы — ноль красных стикеров
- Между событиями и командами нет политик
- Бизнес-эксперт замолчал в первые 30–40 минут
- Доску нельзя объяснить без технического контекста
Шесть антипаттернов Event Storming
1. CRUD-события
Самый распространённый антипаттерн. Вместо бизнес-фактов появляются события из словаря баз данных: Created, Updated, Deleted, Saved.
EmployeeCreated — что это значит? Новый сотрудник вышел на работу? Завели запись для онбординга? Восстановили удалённый аккаунт? Три разных ситуации с разной логикой, но одно событие.
Бизнес-факт в Event Storming — это то, что значимо для бизнеса и занесено в журнал аудита. Тест: «Если через год нас спросят, когда это произошло, — ответит ли это событие на вопрос?» EmployeeCreated не ответит. «Оффер принят кандидатом» — ответит.
EmployeeCreated — что это значит? Новый сотрудник вышел на работу? Завели запись для онбординга? Восстановили удалённый аккаунт? Три разных ситуации с разной логикой, но одно событие.
Бизнес-факт в Event Storming — это то, что значимо для бизнеса и занесено в журнал аудита. Тест: «Если через год нас спросят, когда это произошло, — ответит ли это событие на вопрос?» EmployeeCreated не ответит. «Оффер принят кандидатом» — ответит.
2. Технические события
На доске появляются детали реализации: «HTTP-запрос получен», «Запись сохранена в БД», упоминания технологий — Kafka, Redis, PostgreSQL.
Это сигнал: команда переключилась с языка домена на язык системы. Бизнес-эксперт не знает, что такое Kafka, — и именно поэтому замолкает.
Правило: если событие нельзя объяснить финансовому директору за 10 секунд, оно техническое.
Это сигнал: команда переключилась с языка домена на язык системы. Бизнес-эксперт не знает, что такое Kafka, — и именно поэтому замолкает.
Правило: если событие нельзя объяснить финансовому директору за 10 секунд, оно техническое.
3. Отсутствие политик
Между событием и командой нет сиреневого стикера. Бизнес-логика автоматики невидима.
«Когда оффер принят → запустить онбординг» — это политика. Без неё доска превращается в набор разрозненных фактов. Непонятно, кто и почему инициирует следующее действие.
Отсутствие политик — признак того, что команда не разобралась в бизнес-правилах. Либо не задала вопрос «что происходит дальше автоматически?».
«Когда оффер принят → запустить онбординг» — это политика. Без неё доска превращается в набор разрозненных фактов. Непонятно, кто и почему инициирует следующее действие.
Отсутствие политик — признак того, что команда не разобралась в бизнес-правилах. Либо не задала вопрос «что происходит дальше автоматически?».
4. Ноль hotspot'ов
После трёх часов работы на доске нет ни одного красного стикера.
Два объяснения: либо процесс идеально понятен всем — что крайне редко, — либо команда не докопалась до противоречий, а бизнес-эксперты замолчали.
Hotspot'ы — это главный результат хорошей сессии. Именно здесь прячутся разные понимания одного термина, неясные зоны ответственности и непрописанные бизнес-правила.
Два объяснения: либо процесс идеально понятен всем — что крайне редко, — либо команда не докопалась до противоречий, а бизнес-эксперты замолчали.
Hotspot'ы — это главный результат хорошей сессии. Именно здесь прячутся разные понимания одного термина, неясные зоны ответственности и непрописанные бизнес-правила.
5. Неправильные акторы
На доске — системы и сервисы: CRM, UserService, HRSystem. Вместо бизнес-ролей: Рекрутер, HR-менеджер, IT-администратор.
Когда актором становится система, исчезает вопрос «кто принимает решение?». Система не принимает решений — её настраивает человек с определённой ролью и мотивацией.
Когда актором становится система, исчезает вопрос «кто принимает решение?». Система не принимает решений — её настраивает человек с определённой ролью и мотивацией.
6. Deliverable Obsession
Один человек — обычно техлид или аналитик — заполняет доску. Остальные наблюдают. Разговора нет.
Event Storming — это разговор, а не артефакт. Ценность создаётся в процессе обсуждения и столкновения точек зрения, а не в красиво заполненной доске.
Event Storming — это разговор, а не артефакт. Ценность создаётся в процессе обсуждения и столкновения точек зрения, а не в красиво заполненной доске.
Чек-лист симптомов
Прверь себя. Если находишь три и более — это не Event Storming.
- В названиях событий есть слова: Created, Updated, Deleted, Saved, Sent
- На доске упоминаются технологии: HTTP, SQL, REST, Redis, Kafka, PostgreSQL
- Акторы — системы или сервисы, а не бизнес-роли
- Команды выглядят как endpoint'ы: POST /users, PATCH /orders/{id}
- После трёх часов работы — ноль красных стикеров
- Между событиями и командами нет политик
- Бизнес-эксперт замолчал в первые 30–40 минут
- Доску нельзя объяснить без технического контекста
Хорошая и плохая доска: наглядно
Плохая доска

Хорошая доска

Разница очевидна даже без пояснений. На плохой доске нет ни одной политики, нет hotspot'ов, акторы — системы, а не люди. На хорошей — видна бизнес-логика, вопросы к разрешению и реальные участники процесса.
Почему это происходит
Антипаттерны — не ошибки отдельных людей. Это системные причины.
Состав только из разработчиков. Некому сказать «у нас это называется иначе». Команда использует технический язык, потому что другого не знает.
Мышление от системы, а не от процесса. Привычный вопрос — «что делает наш код?». Нужный вопрос — «что происходит в бизнесе?». Переключиться сложно без фасилитатора.
Спешка к реализации. Event Storming воспринимается как формальность перед спринтом. Команда хочет «закрыть задачу», а не разобраться в домене.
Нет фасилитатора с DDD-экспертизой. Без него никто не остановит появление технических событий и не задаст нужные вопросы.
Страх неопределённости. Hotspot'ы — это признание, что команда чего-то не знает. Некоторые команды избегают их, чтобы «выглядеть готовыми».
Состав только из разработчиков. Некому сказать «у нас это называется иначе». Команда использует технический язык, потому что другого не знает.
Мышление от системы, а не от процесса. Привычный вопрос — «что делает наш код?». Нужный вопрос — «что происходит в бизнесе?». Переключиться сложно без фасилитатора.
Спешка к реализации. Event Storming воспринимается как формальность перед спринтом. Команда хочет «закрыть задачу», а не разобраться в домене.
Нет фасилитатора с DDD-экспертизой. Без него никто не остановит появление технических событий и не задаст нужные вопросы.
Страх неопределённости. Hotspot'ы — это признание, что команда чего-то не знает. Некоторые команды избегают их, чтобы «выглядеть готовыми».
Роадмап исправления
Не нужно выбрасывать текущую доску. Можно исправить её за 1–2 часа.
Шаг 1. Диагностика. Прогони чек-лист симптомов по текущей доске. Зафиксируй, что нашёл.
Шаг 2. Состав. Пригласи бизнес-эксперта или product owner'а на следующую сессию. Без него следующие шаги будут угадыванием.
Шаг 3. Переименование CRUD-событий. Для каждого Created/Updated/Deleted задай вопрос: «Что именно произошло в бизнесе?» EmployeeCreated → «Оффер принят кандидатом», «Перевод сотрудника оформлен», «Аккаунт восстановлен» — три разных события.
Шаг 4. Удали технические события. Всё, что упоминает HTTP, SQL, очереди, сервисы — убрать. Если без этого событие теряет смысл — значит, смысла в нём не было.
Шаг 5. Добавь политики. После каждого события задай вопрос: «Что происходит дальше автоматически?» Ответ — политика. Запиши на сиреневом стикере.
Шаг 6. Найди hotspot'ы. Три вопроса для каждого события и политики: все понимают одинаково? Кто принимает решение? Что если что-то идёт не так? Несогласие → красный стикер.
Шаг 7. Проверь читаемость. Попроси бизнес-эксперта прочитать доску вслух — без подсказок. Где он спотыкается, там проблема.
Шаг 1. Диагностика. Прогони чек-лист симптомов по текущей доске. Зафиксируй, что нашёл.
Шаг 2. Состав. Пригласи бизнес-эксперта или product owner'а на следующую сессию. Без него следующие шаги будут угадыванием.
Шаг 3. Переименование CRUD-событий. Для каждого Created/Updated/Deleted задай вопрос: «Что именно произошло в бизнесе?» EmployeeCreated → «Оффер принят кандидатом», «Перевод сотрудника оформлен», «Аккаунт восстановлен» — три разных события.
Шаг 4. Удали технические события. Всё, что упоминает HTTP, SQL, очереди, сервисы — убрать. Если без этого событие теряет смысл — значит, смысла в нём не было.
Шаг 5. Добавь политики. После каждого события задай вопрос: «Что происходит дальше автоматически?» Ответ — политика. Запиши на сиреневом стикере.
Шаг 6. Найди hotspot'ы. Три вопроса для каждого события и политики: все понимают одинаково? Кто принимает решение? Что если что-то идёт не так? Несогласие → красный стикер.
Шаг 7. Проверь читаемость. Попроси бизнес-эксперта прочитать доску вслух — без подсказок. Где он спотыкается, там проблема.
Чек-лист «как надо / как не надо»
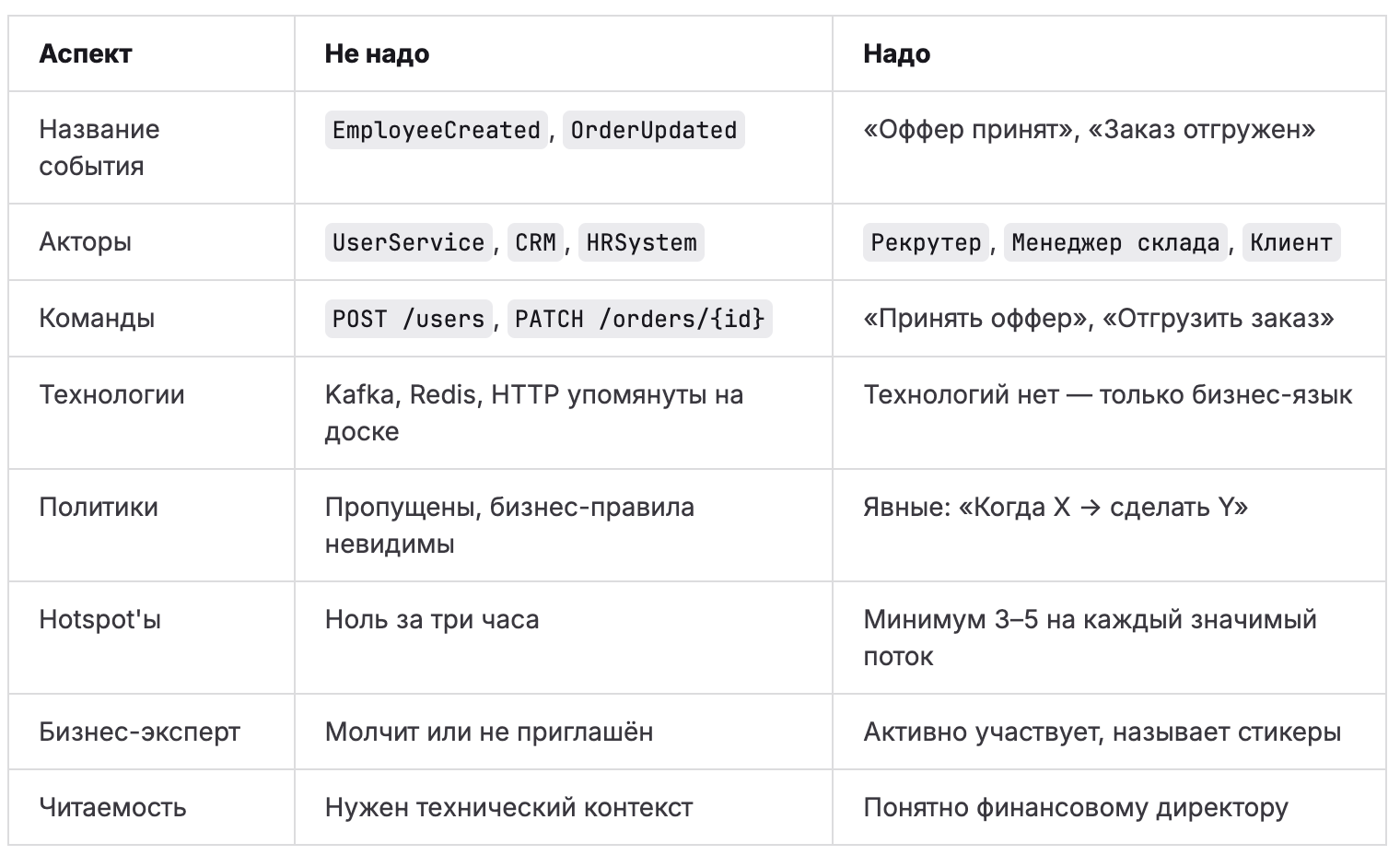
Итог и следующий шаг
Технические схемы — полезный инструмент, но не в Event Storming. Когда доска заполнена CRUD-событиями и системами-акторами, команда теряет главное: общий язык между бизнесом и разработкой.
Хорошая сессия заканчивается не красиво заполненной доской, а списком hotspot'ов для разрешения и бизнес-языком, который все в комнате понимают одинаково.
Следующий шаг: возьми последнюю сессию и прогони чек-лист симптомов. Если нашёл три и более пункта — запланируй ретроспективу доски с бизнес-экспертом. Один час пересмотра сейчас сэкономит месяцы переделок потом.